5G边缘计算网关/工业CPE/工业路由器
工业级 | 可扩展IO板 | 5G双模双卡 | 光口+WIFI6 | VPN组网

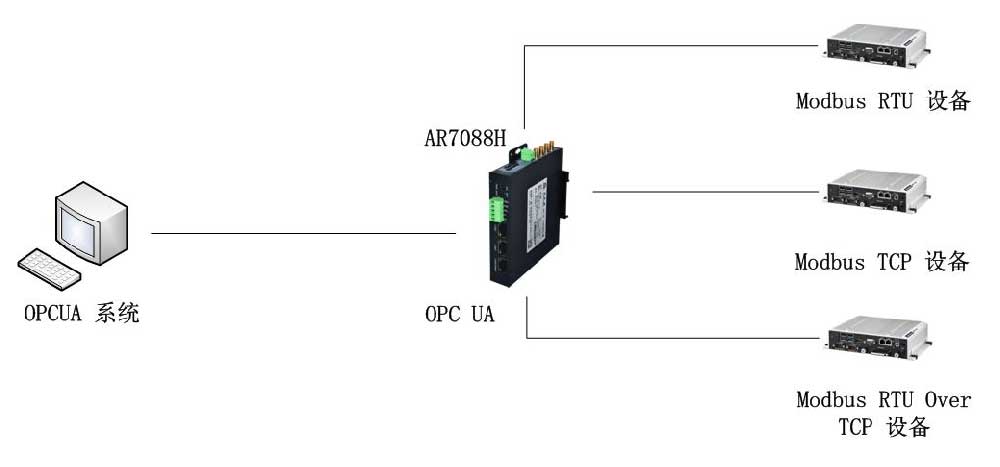
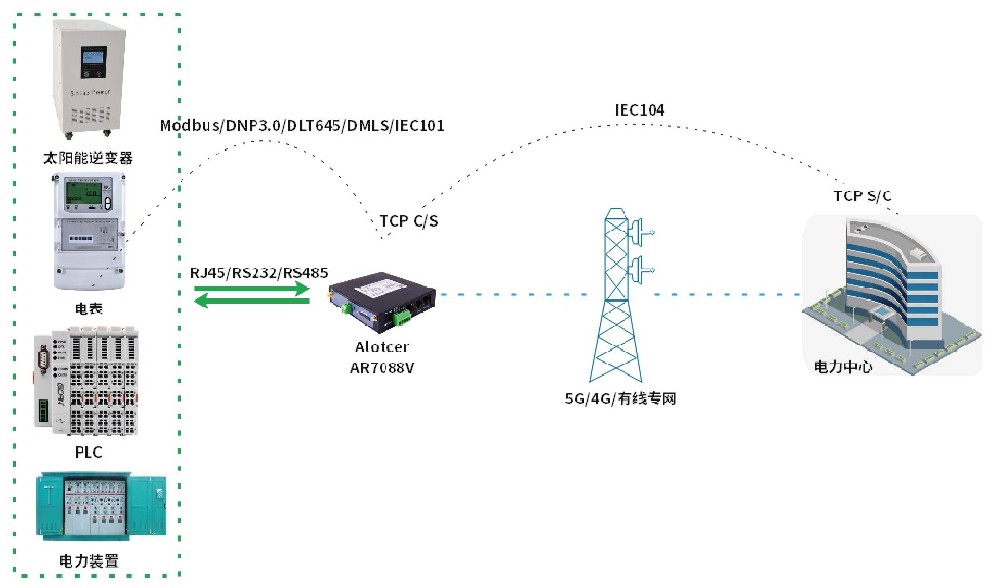 爱陆通电力通信管理机应用篇-modbus转IEC104
爱陆通电力通信管理机应用篇-modbus转IEC104
 嵌入式硬件开发三个阶段的流程
嵌入式硬件开发三个阶段的流程
 集中式DTU通信解决方案-智能配网
集中式DTU通信解决方案-智能配网
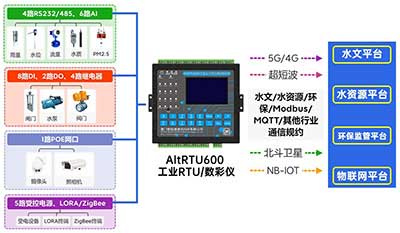 5G视频RTU 视频数采仪 数据采集传输仪
5G视频RTU 视频数采仪 数据采集传输仪