
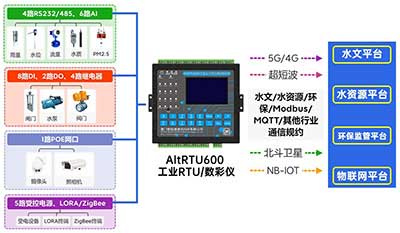
5口工业级路由器/网关/CPE-AR7091F
AR7091F是一款工业物联网蜂窝路由器,它已在M2M领域得到广泛应用,如智能交通、智能电网、邮政服务、工业自动化、遥测金融、销售点系统、供水、环境保护、邮政、天气等。

 5G工业路由器的双卡双待是什么?
5G工业路由器的双卡双待是什么?
 偏远监测站 “数据孤岛” 如何破局?工业路由器 + I···
偏远监测站 “数据孤岛” 如何破局?工业路由器 + I···
 集中式DTU通信解决方案-智能配网
集中式DTU通信解决方案-智能配网
 5G视频RTU 视频数采仪 数据采集传输仪
5G视频RTU 视频数采仪 数据采集传输仪
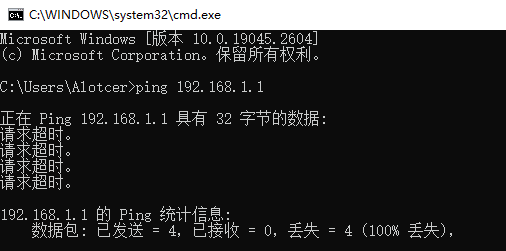
做工业通信运维的人,几乎都依赖ping来判断链路状态。ping通了,就觉得没问题;ping不通,才开始排查。但这个逻辑在很多场景下是错的。一个真实案例:某开关站频繁投退,ping主站丢包率0%,延迟20ms,所有指标正常,但业务就是在断。那么可能问题是出在ICMP和TCP的机制差异上。
ping基于ICMP协议,工作方式非常简单:本地发一个EchoRequest,对方回一个EchoReply,完事。
它不建立连接,不维护状态,不编号,不确认。每一次ping都是独立的、一次性的"喊话"。
ping能通,只证明一件事:IP层的物理通路是通的。
但工业通信协议(比如IEC104)跑在TCP上。TCP的工作方式完全不同:
先三次握手建立连接
每个数据包带序列号,对方必须回复确认
中间经过的每一台NAT设备,都会维护一张"连接登记表",记录这条TCP连接的状态
关键点来了:这张登记表有超时时间。4G运营商环境下,这个超时通常在5分钟左右。超时之后,NAT会删除这条记录。
记录一删,后续情况是这样的:
主站发来的数据包,NAT查不到对应条目,直接丢弃
DTU发出的数据包,NAT当作新连接分配新端口,主站不认识,同样丢弃
TCP连接实际已经断了,但ICMP不查登记表,ping照样能通
ping证明路在,TCP证明路通。路在不等于路通。
有线网络的NAT通常只有一层,超时时间较长,连接相对稳定。
4G无线通信要经过至少三层NAT:
第一层是CPE,负责本地路由转换
第二层是基站网关,属于无线接入网NAT
第三层是运营商CGNAT,负责公网地址转换
每一层都有自己的连接登记表,都有独立的超时机制。TCP长连接在这种多层NAT环境下,天然脆弱。不是设备质量差,是架构决定的。
这也是为什么同一个站点,换了光纤就好了——有线网络没有基站切换、没有多层NAT超时这些中间变量。
走过弯路之后,整理出一套高效的排查路径,实际操作可以把三天压缩到几个小时:
检查CPE指示灯状态
查看4G关键指标:RSRP(信号强度)、SINR(信号质量)
确认是否存在基站频繁切换
判断标准:RSRP低于-90dBm属于信号弱,需要加装放大器或调整天线位置;基站频繁切换说明连接不稳定,需要锁定基站。
这步能解决信号弱和基站切换问题。如果信号满格仍然掉线,进入下一步。
调出主站最近的投退日志,重点看每次投退前是否有规律性报文:
50号报文(加密认证请求):如果每次投退前都出现,说明TCP连接已断,主站在尝试重建
监控帧中断、U帧中断:说明应用层通信已经中断
核心操作:主站和DTU两端同时抓包,对比报文。 单看一端极易误判。主站发了但DTU没收到,或者DTU发了但主站没收到,这才是真实的链路状态。
不要只做一次ping,要做持续性测试:
ping-t 持续ping,观察是否存在间歇性丢包
tracert 查看路由跳数,判断是否绕路
telnetIP端口 直接测试TCP端口连通性
分时段测试(白天与晚上、工作日与周末),判断是否因网络负载导致NAT超时加速
判断标准:ping正常但TCP连接不稳定,问题在应用层,不在网络层;特定时段不稳定,大概率是NAT超时被加速触发。
优先级排序:光纤>有线网络>换运营商>优化无线方案
如果条件允许,直接上光纤。有线网络不存在多层NAT超时和基站切换问题,稳定性有本质差异。换了通信方式后问题消失,基本可以确认是原通信方式的架构缺陷。
实际经验是:我们最终换了光纤才解决。无线通信再怎么优化,稳定性也不如有线。
ping是最低限度的测试,不能代表业务层状态。 ICMP不查连接登记表,NAT转发它不需要维护任何状态。下次遇到通信故障,先抓报文,别先ping。
报文分析才是定位问题的核心手段。 指示灯会误导,ping会误导,但报文记录的是真实发生的通信行为。这次排查的突破口,就是从50号报文的规律中找到的。
无线通信的TCP长连接存在结构性短板。 多层NAT的连接登记表超时,是无线通信场景下TCP断连的主要原因。这不是某个设备的问题,是4G架构的固有特性。有光纤条件的场景,优先走有线,这不是"无线不好",是"无线的复杂度被低估了"。